用 Python 下載科大 LMES 檔案
故此我寫了一個 Python 小程式,好讓我可以快一點把它們都下載回來(注意,本人不保證程式的正確性,及只在 Linux 上測試)。
先複製下面的程式碼,儲存成一個 .py 檔案:
from HTMLParser import HTMLParser
import os
import urllib2
#config
urlToScan = 'http://lmes2.ust.hk/portal/tool/xxxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx'
cookieValue = 'xxxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxxx.lmes5.ust.hk'
class MyHTMLParser(HTMLParser):
started = False
currentFile = {}
currentFolder = {}
currentFolderDepth = 0
isFolder = False
def __init__(self):
HTMLParser.__init__(self)
def handle_starttag(self, tag, attrs):
if tag == "td":
if len(attrs) == 0:
pass
else:
for(variable, value) in attrs:
if variable == "style" and value.startswith("text-indent:"):
currentFolderDepthStr = value.split("text-indent:")[1]
currentFolderDepthStr = currentFolderDepthStr.split("em")[0]
self.currentFolderDepth = int(currentFolderDepthStr)
elif tag == "a":
if len(attrs) == 0:
pass
else:
haveTitle = False
for (variable, value) in attrs:
if variable == 'title':
haveTitle = True
if haveTitle == True:
for (variable, value) in attrs:
if variable == "href" and value.startswith("http") and not value.endswith("URL"):
self.currentFile["file"] = value
self.started = True
break
elif variable == "title" and value == "Folder":
self.started = True
self.isFolder = True
break
def handle_endtag(self, tag):
if self.started and tag == "a":
if self.isFolder:
#print self.currentFolderDepth
'ok'
else:
# concat
folderPath = "lect_notes/"
for i in range(0, self.currentFolderDepth):
folderPath = folderPath + self.currentFolder[i]["name"] + "/"
# save the file
try:
os.makedirs(folderPath)
except:
'path exists, nothing to handle'
filePath = folderPath + self.currentFile["file"].split("/")[-1].replace("%20", " ")
print "Downloading: " + filePath
opener = urllib2.build_opener()
opener.addheaders.append(('Cookie', 'JSESSIONID=' + cookieValue))
f = opener.open(self.currentFile["file"])
fileContent = f.read()
f.close()
with open(filePath, 'w') as fileToSave:
fileToSave.write(fileContent)
print "Saved: " + filePath
self.currentFile = {}
self.started = False
self.isFolder = False
def handle_data(self, data):
if self.started:
if data.strip() != '':
if self.isFolder:
tempFolderList = {}
for i in range (0, self.currentFolderDepth):
if i in self.currentFolder:
tempFolderList[i] = self.currentFolder[i]
tempFolderList[self.currentFolderDepth] = {}
tempFolderList[self.currentFolderDepth]["name"] = data.strip()
self.currentFolder = tempFolderList
else:
self.currentFile["name"] = data.strip()
print "Starting"
opener = urllib2.build_opener()
opener.addheaders.append(('Cookie', 'JSESSIONID=' + cookieValue))
f = opener.open(urlToScan)
urlContent = f.read()
f.close()
print "Parsing page"
hp = MyHTMLParser()
hp.feed(urlContent)
print "Finished"
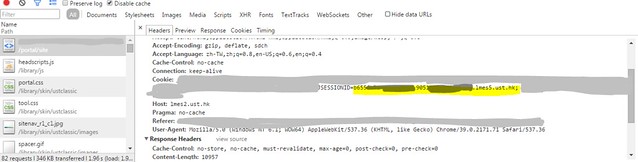
用自己的帳戶登入 LMES。登入後用瀏覽器的 Inspector,找出 HTTP Request 的 SESSION ID,這裡是 JSESSIONID,由 = 後複製到 ; 前,取代程式中 cookieValue 的內容:
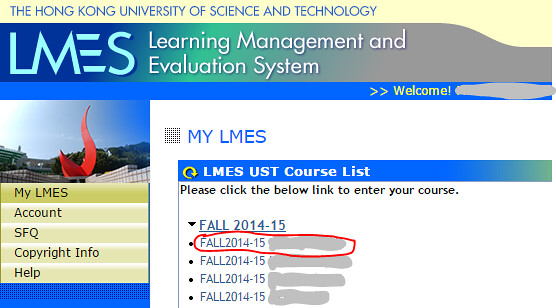
再點選所需科目:
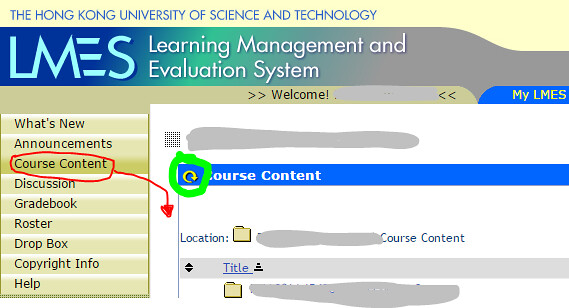
點選 Course Content,利用新 Tab 的方式點擊綠色圈內的連結:
先按綠色圈內的掣以打開全部資料夾,再刪除網址上的 ?panel=Main,進入該網址,確認資料夾都是打開的,複製那網址,取代 urlToScan 的值

最後以 Python 執行,檔案會儲存在執行資料夾內的 lect_notes 內。要下載其他科,就是修改 urlToScan 再執行就行了:

本文連結